NVIDIA Jetson Nano: Communication with industrial PLC using OPC UA

The Jetson Nano is a great device for small experiments with AI. But it can also being used for simple AI tasks in an industrial environment. In this project, you can find an example for transmitting some numerical data from the PLC to the Jetson via OPC UA. After processing in a neural net or something else, the result will be returned to the OPC interface. The PLC can do further processing or trigger a reaction based on the result.
What you need:
- Jetson Nano flashed with latest Jetpack and ONNX Runtime installed
- (Optional: Full Tensorflow installation on Jetson)
- Neural network model or other task. Otherwise you can only test the bare communication between Jetson and PLC
- Industrial PLC with configured OPC UA server
- (Optional: Raspberry Pi flashed with latest Raspberry OS and Codesys Runtime service installed & running)
- Ethernet cable
- (Network switch, only strictly required if you don’t use WiFi to go online with Codesys on the RasPi)
In this example tutorial, a Raspberry Pi (3B) with Codesys Runtime is used as PLC with activated OPC server. You can also use any other PLC, for example a Siemens S7 CPU with TIA.
All scripts and source code used in this project can be found in my Github repositories:
- OPC UA communication: https://github.com/jschw/Jetson-OPCUA-Communication
- Example neural network model: https://github.com/jschw/Keras-Timeseries-Classification
Preparing the Raspberry as PLC
Let’s start with the test setup on the Raspberry. If you want to use a PLC other than Raspberry/Codesys, please skip this section and continue with the preparation of the Jetson and the OPC interface.
Create a new project for the RasPi Runtime and add a global variable list to the main application.

In this variable list, you have to define your interface to the Jetson. Declare some variables you want to share and keep in mind, you always need a trigger (otherwise the Jetson don’t “know” when to do some calculations!). And it’s always not bad to provide some status, error and logging variables if something goes wrong. This is an example or proposal how to do it, it may vary from usecase to usecase:

With a Symbol Configuration, you can make it visible on the OPC server. Add it and check the OPC option:
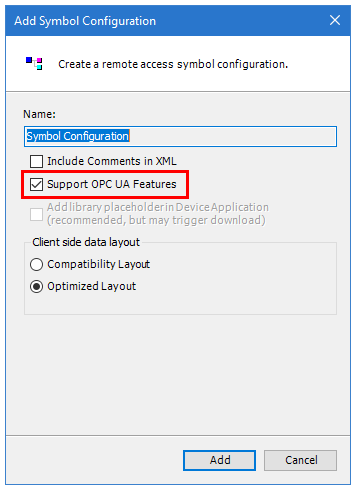
After declaring the variables, you have to set the visibility for each variable separately (double click on Symbol Config in the project tree). Please note, that at least one of the variables in the list must be referenced in the main program and the project have to be compiled. Otherwise, the global var list is not visible in the Symbol Config. Maybe a bug in Codesys!?
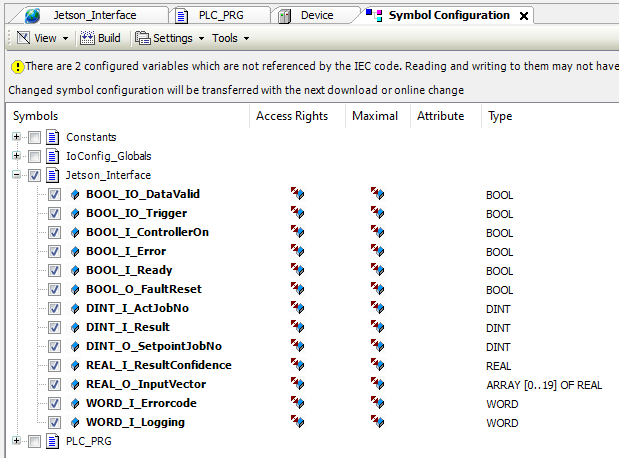
To send a trigger and receive the result, I have written a simple control structure as main program. Please keep in mind that it’s very basic and only for testing purposes.
Next thing is to configure the address of the built-in ethernet port eth0 to a static address. For some reason, the network configuration utility of Raspberry OS has no effect on the configuration. No problem — GUIs are for losers! :D Edit the config file with nano:
sudo nano /etc/dhcpcd.confUncomment the marked configuration lines and enter your desired IP address, save the file and then reboot the RasPi.

Setting up the Jetson
The first thing we want to setup on the Jetson is the configuration of the OPC connection to the PLC (OPC server). We will use the library FreeOpcua. But this is very cumbersome and inflexible to configure and use. So I wrote a simple wrapper function. The connection and all shared variables can be declared in one JSON configuration file.
But first, you have to get to know the namespace index and indices of each variable! For example, you can use the tool UAExpert (https://www.unified-automation.com/de/downloads/opc-ua-clients.html). After connection to the server you can navigate to the exposed global variable list (or in general: the interface variables).
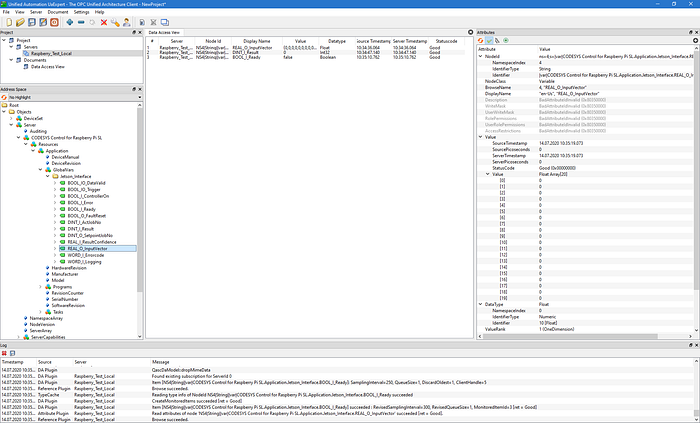
Under “NodeId” in “Attributes”, you can copy&paste the namespace index and the Identifier of each variable. There is also some info displayed like the variable type. It’s important to know that detail if you want to manipulate values on the server with the Jetson.
The structure of the JSON file looks like this:
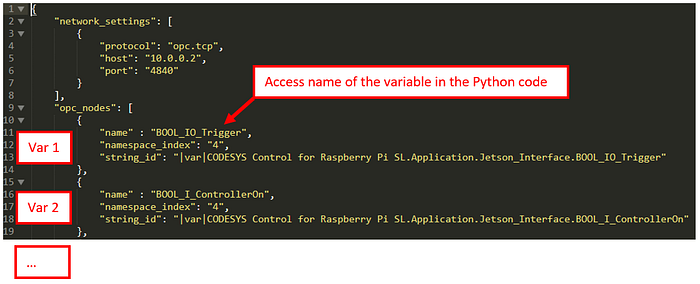
You can add as much variables as you like! The access variable name is the name which references to the identifier on the OPC server and you will use this name to get or set a value from the Python/client side. This name don’t have to be the same as used on the interface/server side. But different names may lead to confusion… ;)
If not already done, copy all the content of the folder “Client_application” of my Github repo to a folder on the Jetson. It contains a neural network model (see next section) for testing and all required scripts. You need at least read permissions to this folder.
Don’t forget to set a static IP address for eth0. On the Jetson, you can use the network utility. Check the two options if not already checked.
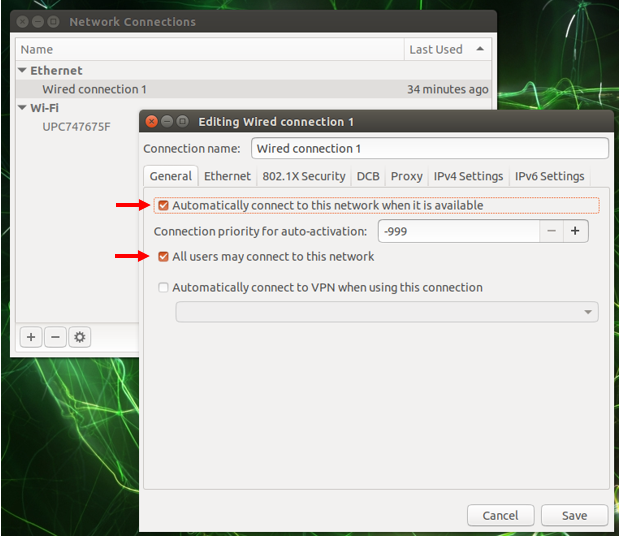
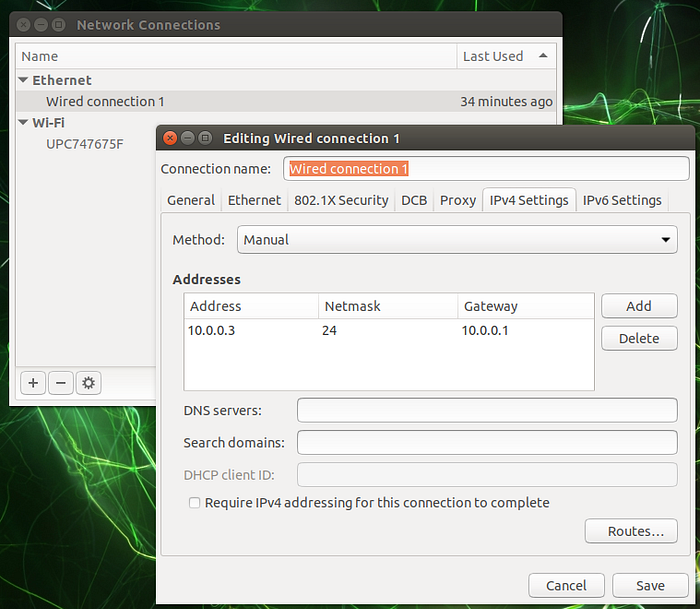
Now it’s time to take a look into the main program file which handles all the connection things and data processing.
In order to use my implementation with the JSON config file, one additional import is needed. The connection can be established with just one line of code:
from opcuaTools import getOpcConnection...OBJ_OpcClient, OBJ_OpcNodes = getOpcConnection(WORD_OpcConfigFilePath)
If the host is available, a client connection object and a dictionary of all nodes configured in the JSON file will be returned.
Retrieving data from the server can be done this way (here: BOOL_IO_Trigger is the access name defined in JSON file):
BOOL_Trigger = OBJ_OpcNodes['BOOL_IO_Trigger'].get_value()Writing data on the interface server is just as easy:
OBJ_OpcNodes['BOOL_I_Ready'].set_value(BOOL_Ready, ua.VariantType.Boolean)Please note that it’s important to set the correct ua.VariantType for each variable! The datatype of the variables can be determined e.g. with UAExpert.
After starting the main script, the two status variables ControllerOn and Ready should change to TRUE and Error to FALSE:
python3 opc_inference_task_runner.py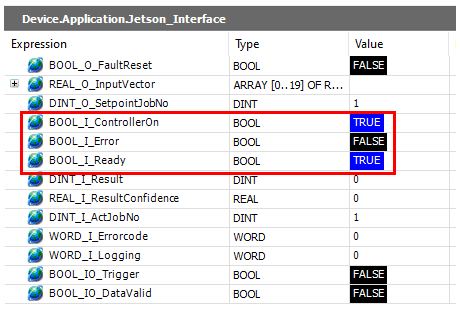
(Note: The running script can be stopped by pressing CTRL+C twice.)
Now you can read and write values from and to an OPC server which runs on a PLC!
Running inference of an AI model
In the last section of this article, I want to demonstrate how to use this OPC communication for running AI models alongside a PLC in industrial processes. Of course, it don’t have to be an AI model or neural network. It can be everything that can’t be done on the PLC or what needs special hardware or software environments. A neural network is a good example for this.
I decided to use a simple neural network (NN) which can classify the characteristics of a series of numerical values (See: LINK).
In common, a PLC is processing mainly numerical values, e.g. measured with sensors like temperature, pressure or distance. The NN we will use in this example expects a 2-dimensional tensor with the shape (1,20). This means, we will feed 10 sample points (consisting of one x and one y value) and get a vector with a confidence value for each class as result.
Because larger NN often need a lot of time to process the input, we try to optimize the processing latency as good as possible. With ONNX, there is an open exchange format and high performance runtime available (See: http://onnx.ai/).
So we have to convert first the NN model to ONNX format:
After successful conversion, you get some additional info for running the inference:
tf executing eager_mode: True
tf.keras model eager_mode: False
The ONNX operator number change on the optimization: 23 -> 15
The maximum opset needed by this model is only 9.The model is being loaded with the following line in opc_inference_task_runner.py:
sess = onnxrun.InferenceSession(WORD_NeuralNetworkModelFilePath)Model inputs and outputs can be determined with a tool like Netron (https://github.com/lutzroeder/netron) or programmatically in the code:
WORD_InputName = sess.get_inputs()[0].name
WORD_OutputName = sess.get_outputs()[0].name
WORD_InputShape = str(sess.get_inputs()[0].shape)The main task, run the feed forward step, postprocess the result data and return values to the interface is pretty easy:
These lines will return the predicted class (Int32/DINT) and the confidence value in percent (Float/REAL).
Now, go online on your PLC (e.g. the RasPi with Codesys ) and set the trigger to “True” and do the inference on the input values set in Codesys:
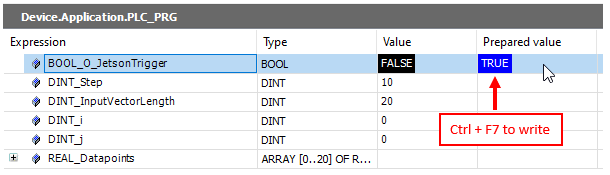
If everthing works, the Jetson will return the values which can be displayed in the live view:
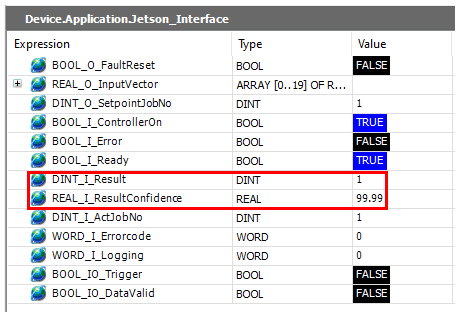
Try experimenting with some other values or the ones commented out in the variables section. As we can see here, the result is correct: The predicted class 1 is a line with a confidence value of 99.99 %.
That’s it! :)
Some thoughts about performance
Maybe, in some cases such as doing analytics after the process or in time-insensitive tasks, it’s not important to deliver a result super fast. But when it comes to industrial processes (e.g. routing in logistic processes, production, real-time control), processing time matters, always!
ONNX is a huge step in inference optimization of neural networks. To demonstrate that, I created two versions of the task runner main program: One uses ONNX, the other a full Tensorflow Backend with the Keras high-level API. The result is really impressive!
With the tool htop, the memory consumtion can be displayed. The marked process also includes the overhead for the Python core.

This is a simple comparison of memory consumption and processing time of both inference tasks (incl. Python core):
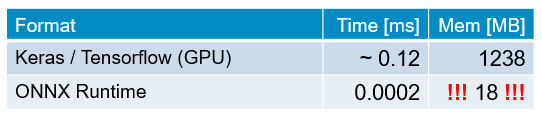
Though the model is a very small one, the inference time is very impressive! On top of this time, the latency of the network communication has obviously to be added. But even then it should be fast enough in most cases.
I strongly recommend to put always some effort in optimizing a model for inference. Depending on the usecase, there are of course some other high performance runtimes beside ONNX. For example TensorflowLite (https://www.tensorflow.org/lite) or NVIDIA TensorRT (https://developer.nvidia.com/tensorrt). If you plan to exchange your model between various platforms, than ONNX should be a good choice at the moment.
Conclusion
This article points out a method to solve the “missing link” problem between AI technologies in science and the industrial environment. These can be used to extend the possibilities of the “classic” ways to process numerical data on PLCs.
In addition to a PLC, a device like the Jetson can also handle tasks in computer vision like object detection/tracking.
It is also possible that in the next few years more hardware with AI accelerators and some type of fieldbus included will be released (e.g. ProfiNet or EtherCAT). For time-sensitive processes, this can be an option to lower the communication latency.
